
The Harness Is the Artifact - TCR 05/08/26

The 20-Second Scan
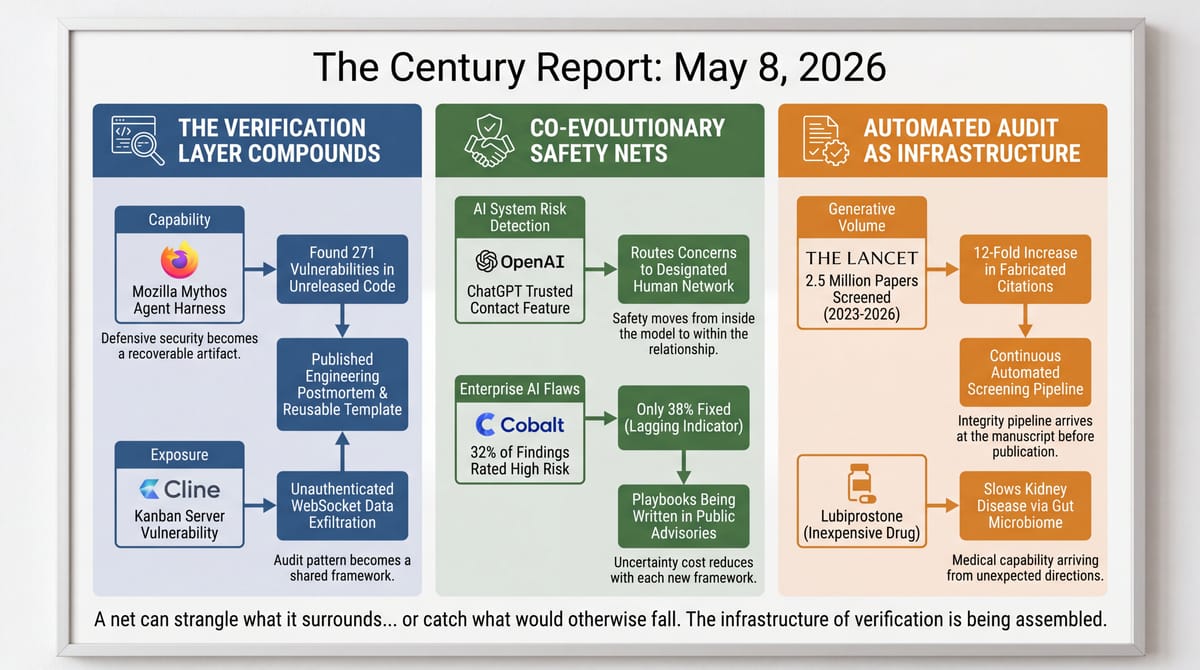
- Mozilla published a detailed engineering postmortem describing the agent harness, prompts, and validation pipeline behind Anthropic's Claude Mythos finding 271 vulnerabilities in unreleased Firefox 150 code.
- A Tohoku University clinical trial of 150 patients with chronic kidney disease found that lubiprostone - a common, inexpensive constipation medication - slowed the decline of kidney function by improving gut bacteria that boost spermidine production.
- OpenAI launched a Trusted Contact feature for adult ChatGPT users that notifies a designated friend or family member when conversations indicate serious safety concerns - extending the safety architecture introduced after a teenager's death last year.
- A critical vulnerability in Cline's Kanban server lets any website silently exfiltrate workspace data and inject commands into AI coding agents' terminals through unauthenticated WebSocket endpoints.
- F5's annual State of Application Strategy report found 77% of enterprises now prioritize AI inference over training, with the average organization running or evaluating seven AI models simultaneously across hybrid multicloud environments.
- A Cobalt penetration testing analysis found that 32% of all AI and LLM security findings are rated high risk - 2.5 times the rate of severe flaws in conventional applications - with only 38% of high-risk LLM issues fixed.
- An audit of 2.5 million biomedical papers using automated screening found 12 times more publications with fabricated citations in 2025 than in 2023, the first study to estimate the scale of fake citations in biomedical literature.
- The University of Cambridge published the first study putting a commercial AI toy in front of children ages 3-5, finding structural disruptions to conversational turn-taking and concerns about three-way social play.
Track all of the arcs The Century Report covers here:
The 2-Minute Read
The signal yesterday traces a sharpening of the verification layer being assembled around frontier AI capability. Anthropic's Mythos found 271 real vulnerabilities in unreleased Firefox code with what Mozilla itself describes as "almost no false positives," and the published engineering postmortem now exists as a recoverable artifact: a description of the agent harness, the prompts, the workflow, the criteria. The Century Report covered the Mythos-Firefox numbers in late April when Mozilla first disclosed them. What is new is that the methodology has now been published in detail, and the same week, a critical Cline vulnerability shows the inverse - AI coding agents themselves are accumulating attack surface that any website a developer visits can exploit. Both stories describe the same dynamic: capability and exposure compounding on the same clock, with the verification frameworks arriving in increments behind both.
OpenAI's Trusted Contact feature and Cobalt's penetration testing data are the same dynamic from different angles. ChatGPT now allows adult users to designate someone who will be notified when the system detects serious safety concerns - the structural extension of the parental controls introduced after a teenager's death last year. Cobalt's report shows that AI deployments are producing severe security findings at 2.5 times the rate of conventional applications, and only 38% of those high-risk findings are being fixed. The verification gap is documented from both ends: the consumer-safety surface is expanding through opt-in features that did not exist a year ago, and the enterprise-security surface is expanding faster than organizations can patch it.
The biomedical citation audit is what scientific verification looks like after generative AI has touched the literature. Researchers screened 2.5 million papers and found a 12-fold increase in publications containing fabricated citations between 2023 and 2025, with rates that the authors themselves describe as conservative underestimates. Alongside it, a Tohoku University trial showed that an inexpensive existing drug can slow chronic kidney disease through a previously unrecognized gut-microbiome pathway - a pattern of medical capability arriving from unexpected directions, on a clock the dialysis economy was not pricing against. The infrastructure of verification and the pace of medical discovery are both being assembled in public, on a compressed clock, in courtrooms and research labs and engineering postmortems alike.
The 20-Minute Deep Dive
The Mozilla Postmortem and What an AI Audit Layer Actually Looks Like
Mozilla's engineering team published yesterday the most detailed public account yet of how Anthropic's Claude Mythos produced its Firefox 150 vulnerability discoveries. The numbers - 271 vulnerabilities found, almost no false positives - were already public when the April 22 edition of The Century Report covered Mozilla's initial disclosure. What is new is the engineering detail: a description of the agent harness Mozilla built around Mythos, the prompts that drove it, the testing pipeline it accessed, and the criteria by which findings were validated. The postmortem is a published artifact that the next defensive cybersecurity team can read, adapt, and apply to its own codebase.
The Mozilla engineers describe the differentiator as the harness itself. Earlier brushes with AI vulnerability detection had produced what they call "unwanted slop" - plausible-reading bug reports at unprecedented scale that, on investigation, turned out to be largely hallucinated. The Mythos work was different because the harness gave the model the same tools and pipelines that human Mozilla developers use, including the special Firefox build environment used for testing. The model was being placed inside the actual development workflow with a clearly machine-verifiable goal: cause the build process to crash.
What the postmortem demonstrates is that an AI system, when scaffolded correctly, can now perform memory-bug discovery at a rate and accuracy that exceeds what fuzzers and traditional code review produce. The forward read is that this capability is going to become standard. Mozilla itself frames the finding as evidence that "zero-days are numbered" for projects with the engineering discipline to build a harness like this. The structural shift the postmortem describes is that vulnerability discovery is becoming a recoverable artifact rather than tribal knowledge. Each defensive team that publishes its harness, its prompts, its workflow makes the next defensive team's task easier. The verification capacity that had to be built one engineer at a time can now be drafted from a published template.
What this points at is the trajectory of what defensive security looks like when the same capability is in the hands of attackers. The Mozilla postmortem shows what coordinated, sanctioned use produces. The Cline vulnerability disclosed the same day shows what happens when the same class of capability sits underneath a developer's coding agent without the same scaffolding.
The forward read worth holding alongside Mozilla's framing is that the harness is the artifact, not the model. Anthropic's Mythos is a capability; the Firefox-specific scaffolding Mozilla built around it - the build environment, the crash-as-success criterion, the validation pipeline - is what produced the result, and that scaffolding is what other defensive teams can now adapt without negotiating frontier-model access first. The capability layer compounds with frontier releases; the scaffolding layer compounds with every published postmortem.
Cline's Kanban Vulnerability and the Localhost Trust Boundary
Oasis Security disclosed yesterday a critical vulnerability in the Cline AI coding agent's Kanban server, rated CVSS 9.7, that allows any website a developer visits to silently exfiltrate workspace data, inject commands into the agent's terminal, or kill active sessions. The exploit chain progresses from passive reconnaissance to remote code execution entirely from JavaScript on any webpage the developer visits while Cline is running, with no phishing or social engineering required.
The vulnerability stems from missing origin validation and authentication on three WebSocket endpoints that the Kanban server exposes on the local machine. The implicit assumption that bound the design - that binding to localhost confined access to the developer's own computer - turned out to be wrong, because browsers do not enforce cross-origin restrictions on WebSocket connections to localhost in the way they do for standard HTTP requests. A malicious page can connect to the runtime endpoint, harvest workspace context, identify an active task ID, then push commands to the terminal endpoint that the agent processes as if typed by the user.
The risk is amplified by Cline's default "bypass permissions" flag, which lets the AI agent execute shell commands and modify the filesystem without per-action authorization. Trey Ford of Bugcrowd, quoted in the disclosure, framed the broader issue precisely: "Patching Cline to v0.1.66 closes this specific exposure. Auditing every AI tool that opens a local listener is the actual job to be done." The localhost-as-trust-boundary error is systemic across AI coding agent platforms, and Oasis Security noted that the same pattern appeared in their earlier OpenClaw research.
The forward read is that AI coding agents are accumulating attack surface in places their security models did not anticipate. The Century Report has been tracking this arc since the OpenClaw browser exploit research in February. The February 26 edition of The Century Report documented OpenClaw users bypassing anti-bot systems, and the April 21 edition tracked a Google Antigravity agent-manager flaw that could let a security agent escape its sandbox. What yesterday's disclosure adds is that the pattern is now documented across multiple agentic coding tools, with a published advisory that other security researchers will use as a template to audit similar architectures. The verification capacity that had to be discovered one tool at a time is becoming a recoverable framework that the next disclosure can build against.
Trey Ford's framing - that auditing every AI tool opening a local listener is the actual job - points at the specific shape the next year of agent-security work will take. The localhost-as-trust-boundary assumption was inherited from a generation of developer tooling where the only software talking to localhost was the developer's own. Coding agents broke that assumption months ago, and the audit pattern Oasis Security demonstrated against OpenClaw and now Cline is becoming a recoverable template. Each disclosure published at this level of detail shortens the discovery time on the next agent that ships with the same architectural error.
The Trusted Contact Feature and What Co-Evolutionary Safety Looks Like
OpenAI launched yesterday a Trusted Contact feature for adult ChatGPT users that allows them to designate a fellow adult who will receive a notification - delivered as email, text message, or in-app alert - when ChatGPT detects that a conversation indicates serious safety concerns about self-harm or suicide. The feature is opt-in, the contact must accept the invitation within a week, and OpenAI's notification is described as "intentionally limited," sharing no chat details or transcripts.
The feature extends the emergency contact infrastructure that OpenAI introduced alongside parental controls in September, after a 16-year-old took his own life following months of confiding in ChatGPT. Meta has introduced a similar feature alerting parents when teens repeatedly search for self-harm topics on Instagram. The structural significance is that the verification layer for AI-assisted mental health risk is now being assembled inside the products themselves, in the form of features that escalate to humans when automated detection identifies concerning patterns.
The cases that pushed this development into existence are not abstract. Jane Doe v. OpenAI, which the April 11 edition of The Century Report covered, documented a stalker whose ChatGPT account was flagged by the company's automated systems for mass-casualty weapons activity, then restored by a human reviewer the following day. The structural gap between detection and response is the gap that features like Trusted Contact are now beginning to close, one product cycle at a time. The Florida criminal investigation into OpenAI over the Florida State University shooter's alleged ChatGPT use, also covered in April, sits in the same arc.
The deeper read is that the architecture of safety for AI conversation systems is moving from a posture where the model is expected to refuse harmful requests to a posture where humans are kept in the loop through escalation. The "alignment" framing that dominated AI safety discussions a year ago assumed the model itself would handle the safety boundary. The infrastructure being built now assumes the model will escalate to a human network when the boundary is approached. This is co-evolution: two forms of intelligence learning to coexist under frameworks that did not exist before either was deployed at scale, with the frameworks being assembled as the deployments compound. The wonder is that the assumption underwriting the prior architecture - that capability could deploy faster than the human escalation network could be built - is being structurally inverted, with the network arriving inside the product itself.
The structural shift worth marking is that the safety boundary is moving from inside the model to inside the relationship. The earlier alignment frame asked the model to refuse harm on its own; the escalation frame assumes the model will route serious risk into a human network the user designated in advance. That redesign changes what counts as a deployable safety architecture: the question is no longer only whether the model can recognize a crisis, but whether the product has the social infrastructure to route the recognition somewhere a human can act on it. OpenAI's feature is one implementation; the design pattern is general, and other AI conversation systems will be measured against it.
The Cobalt Pen Test Data and the Verification Asymmetry
Cobalt's annual State of Pentesting Report disclosed yesterday that 32% of all AI and LLM security findings discovered during penetration tests are rated as high risk - nearly 2.5 times the rate (13%) of severe flaws found in conventional enterprise security tests. LLM vulnerabilities also have the lowest resolution rate of any application type tested, with just 38% of high-risk issues fixed. One in five organizations Cobalt surveyed reported experiencing an LLM security incident in the past year.
The pattern security professionals describe in the analysis is consistent. AI systems introduce attack surfaces - prompt injection, insecure plugins, model supply-chain risk, unsafe agent behavior, excessive permissions, and over-trusted integrations - that organizations are still learning to defend. The blast radius for AI flaws can be much larger because LLM deployments are connected to internal knowledge bases, code repositories, customer data, and privileged tools. A single weakness can expose multiple systems. And remediation ownership is fragmented across engineering, security, legal, procurement, and business teams, which slows fixes.
But the most telling data point is the 38% remediation rate. Adrian Furtuna, founder and CEO at Pentest-Tools.com, framed it precisely: "What that gap reflects is that development teams don't yet have established patterns for fixing LLM vulnerabilities the way they do for, say, SQL injection or XXE. When they see a prompt injection chain or an insecure tool call boundary, they often don't have a playbook, and that uncertainty stalls action even when the severity rating is clear."
The forward read is that the playbooks are now being written, in published advisories like the Cline disclosure, in engineering postmortems like the Mozilla Mythos report, and in the Cobalt findings themselves. Each new public framework reduces the next team's uncertainty cost. The structural assumption becoming impossible to maintain is that AI deployment can move faster than the security playbook can be written. The playbook is now compounding alongside the deployment, in public, on the same clock - and the curve of playbook quality is starting to bend faster than the curve of new attack surfaces.
The 38% remediation rate Furtuna names is the gap closing on its own clock. SQL injection remediation rates were comparable in the early 2000s before the playbook stabilized; the curve bent once the patterns - parameterized queries, ORM defaults, framework-level escaping - became standard practice rather than expert knowledge. Prompt injection, insecure tool boundaries, and over-permissioned agent integrations are at the same stage now, and the playbook is being written in public through advisories like the Cline disclosure and postmortems like Mozilla's. The remediation rate is a lagging indicator of where the playbook stands today, not a permanent feature of AI security.
The Biomedical Citation Audit and the Compounding of the Verification Layer
A study published yesterday in The Lancet examined 2.5 million academic papers in PubMed Central published between January 2023 and February 2026, screening 97 million references with valid Digital Object Identifiers or PubMed IDs. The automated pipeline identified nearly 3,000 biomedical-science papers that contain fake references that could not be traced to known publications. There were 12 times more publications with fabricated citations in 2025 compared with 2023.
The authors describe their findings as "conservative underestimates" - the lower bound of true prevalence. A manual check of 500 flagged references confirmed that citations were fabricated in seven out of ten cases. Kathryn Weber-Boer of Digital Science, commenting on the analysis, said "the growth in the problem suggests that there is a generative AI component."
The arc The Century Report has been tracking - paper mills, AI-fabricated public regulatory comments, AI-generated CSAM at school scale, fake AI-generated music on streaming platforms - converges with this finding. The volume of synthetic content threatening institutional integrity is growing faster than the institutional response, but the institutional response is now arriving in the form of automated audit pipelines that can screen the entire literature in a single analysis. The March 8 edition of The Century Report documented Northwestern's warning that organized scientific fraud networks were publishing fake research faster than legitimate science could appear, and yesterday's audit gives that integrity crisis a measurable biomedical-literature footprint. Wikipedia's English-edition ban on AI-generated articles, the Nature analysis from April finding 1.6% of 2025 publications contained references to non-existent publications, and yesterday's Lancet study describe the same dynamic from different angles.
The deeper signal is that the same generative capability that produced the verification crisis is now producing the verification infrastructure. Automated screening pipelines that can identify hallucinated citations across millions of papers did not exist three years ago, and they are now being deployed at scale. The forward read is that the next generation of scientific publishing infrastructure will include audit layers that operate continuously rather than after publication, the same way the Mozilla harness operates continuously rather than after release. The structural shift is that verification, like generation, is now compounding.
The same generative capability driving the 12-fold surge in fabricated citations is what made the audit pipeline possible. Three years ago, screening 2.5 million papers against 97 million references was not a project a research team could run; today it is a single analysis that produces a recoverable artifact. The forward read is that continuous citation auditing becomes part of the submission pipeline rather than a forensic exercise after publication, the same way Mozilla's harness operates continuously rather than after release. The integrity crisis and the integrity infrastructure are running on the same curve.
The Other Side
The architecture being eroded across yesterday's signal is the assumption that vulnerability discovery is a scarce, tribal craft - that finding bugs in browser code, fabricated citations across millions of papers, or unsafe trust boundaries in coding agents required years of specialized human expertise that could only be applied one codebase, one paper, one tool at a time. That assumption was the foundation of an entire defensive economics: vendors could ship faster than reviewers could read, publishers could accept faster than auditors could screen, and the gap between deployment and verification was where the costs of opacity were extracted.
Mozilla's published Mythos harness changes the arithmetic. The engineering postmortem is a reusable specification. The harness, the prompts, the build environment, the validation criteria are now public. The Lancet's automated screening of 2.5 million biomedical papers in a single analysis is the same shape applied to scientific literature: an audit that until recently would have required a career's worth of manual reference-checking now runs as a pipeline a journal can integrate at submission.
What this opens up is concrete. The Mozilla engineers who described earlier AI vulnerability reports as "unwanted slop" now have evidence that the right scaffolding turns the same underlying capability into a defensive asset producing 271 real findings with almost no false positives. Kathryn Weber-Boer of Digital Science, who looked at the citation audit and named the generative-AI component driving the surge, will work in a publishing environment where the screening pipeline she described arrives at the manuscript before the fabricated reference does. The defensive playbook that took a decade to write for SQL injection is being written in months for prompt injection, and each published advisory shortens the next team's runway.
The Century Perspective
With a century of change unfolding in a decade, a single day looks like this: AI systems finding 271 real vulnerabilities in unreleased browser code with engineering postmortems published as reusable templates, an inexpensive existing drug slowing chronic kidney disease through a newly mapped gut-microbiome pathway, automated pipelines screening 2.5 million biomedical papers for fabricated citations in a single analysis, ChatGPT building human escalation networks directly into the product, and enterprises shifting from model training toward inference across hybrid multicloud environments. There's also friction, and it's intense - Cline's unauthenticated WebSocket endpoints letting any website exfiltrate workspace data and inject commands into AI coding agents, 32% of AI security findings rated high risk while only 38% are fixed, fabricated biomedical citations multiplying twelve-fold in two years, and AI toys disrupting the conversational turn-taking that preschool children use to build language. But friction generates abrasion, and abrasion exposes the layers underneath. Step back for a moment and you can see it: defensive AI becoming an audit layer for code, decades-old medications finding new clinical roles through microbiome research, synthetic science forcing continuous verification into publishing, conversational AI routing risk back into human relationships, and enterprise inference turning deployment into the main security frontier. Every transformation has a breaking point. A net can strangle what it surrounds... or catch what would otherwise fall.
AI Releases & Advancements
New today
- OpenAI: Released new realtime voice models in the API for speech reasoning, translation, and transcription . (OpenAI)
- NVIDIA Labs: Released
cuda-oxide, an experimental Rust-to-CUDA compiler on GitHub . (GitHub) - Spotify: Released the Save to Spotify CLI, a command-line tool for AI agents to save generated audio as personal podcasts in Spotify . (Spotify Newsroom)
- Modular: Released Mojo v1.0.0b1, the first beta of the Mojo programming language for AI development . (Mojo)
- antirez: Released
ds4, a local inference engine for running DeepSeek 4 Flash models on Apple Metal GPUs . (GitHub)
Other recent releases
- xAI: Launched Connectors on Grok Web, adding deep integrations with everyday apps directly inside Grok . (xAI)
- xAI: Released Quality Mode for image generation and editing via the Grok Imagine API for enterprise developers and teams . (xAI)
- Zyphra: Released ZAYA1-8B, an 8.4B-parameter MoE reasoning model with 760M active parameters trained on AMD hardware, available on Hugging Face and Zyphra Cloud . (Zyphra)
- Anthropic: Added “dreaming” to Claude Managed Agents in research preview, enabling scheduled memory review for long-running agent sessions . (Anthropic)
- Unsloth / NVIDIA: Released LLM training optimizations for Unsloth, including packed-sequence metadata caching and gradient-checkpointing changes for faster training on NVIDIA GPUs . (Unsloth)
- OpenAI: Released GPT-5.5 Instant as ChatGPT’s new default model, with improved factuality, image analysis, web-use decisions, and personalization controls . (OpenAI)
- Anthropic: Released ten financial-services agent templates as Claude Cowork and Claude Code plugins and Claude Managed Agents cookbooks, alongside Microsoft 365 add-ins for Excel, PowerPoint, and Word . (Anthropic)
- Google Nest: Rolled out a Google Home update with Gemini 3.1 voice assistance for early access users and new camera controls, including improved AI event labeling and easier camera feed navigation . (Google Blog)
- Unity: Launched Unity AI in open beta for Unity 6 and above, adding in-editor Ask and Agent modes for AI-assisted game development workflows . (Unity Discussions)
- Airbyte: Launched Airbyte Agents, a context layer for production-grade AI agents . (Product Hunt)
- Google: Released Gemma 4 MTP variants with Multi-Token Prediction, including 31B-it-assistant, 26B-A4B-it-assistant, and E4B-it-assistant models on Hugging Face . (Reddit)
Sources
Artificial Intelligence & Technology's Reconstitution
- Ars Technica: Mozilla says 271 vulnerabilities found by Mythos have "almost no false positives"
- Infosecurity Magazine: Cline Kanban Flaw Lets Websites Hijack AI Coding Agents
- The Verge: ChatGPT's 'Trusted Contact' will alert loved ones of safety concerns
- CSO Online: Pen tests show AI security flaws far more severe than legacy software bugs
- RCR Wireless: F5 report shows enterprises bringing AI inference in-house
- Wired: The New Wild West of AI Kids' Toys
- Nature: OpenAI is under criminal investigation — why chatbots don't always follow the law
- Wired: ChatGPT Has 'Goblin' Mania in the US. In China It Will 'Catch You Steadily'
- Wired: How to Disable Google's Gemini in Chrome
- Ars Technica: Google unveils screenless Fitbit Air and Google Health app to replace Fitbit
- The Verge: Apple's AirPods with cameras for AI are apparently close to production
- The Verge: SpaceX has a $55 billion plan to build AI chips in Texas
- The Verge: OpenClaw and Claude can put your AI-generated podcasts in Spotify
- MediaPost: Meta Reportedly Developing Agentic Assistant For Social Media Users
- The Robot Report: Hugging Face launches agentic toolkit for Reachy Mini
- Wired: This Reggae Band Is in a Nightmare Battle Against AI Slop Remixes
Institutions & Power Realignment
- Fortune: Elon Musk called Anthropic 'evil' 3 months ago. Now he's taking $4 billion to become its data landlord
- Ars Technica: Elon Musk tried to hire OpenAI founders to start AI unit inside Tesla
- TechCrunch: Elon Musk's lawsuit is putting OpenAI's safety record under the microscope
- Wired: Musk v. Altman Evidence Shows What Microsoft Executives Thought of OpenAI
- Guardian: Shivon Zilis, mother of four of Elon Musk's children, testifies in OpenAI trial
- New York Post: Former OpenAI board members describe 'extremely risky' near-merger with Anthropic
- Guardian: Meta sues Ofcom over fines regime for breaches of Online Safety Act
- Guardian: Europe's AI translation industry told it risks reputation by partnering with US firms
- Guardian: UK schools should remove pupils' online photos as AI blackmail threat grows
- CNBC: Paul Tudor Jones says U.S. is late to regulating AI
- New York Times: Howard Lutnick Grilled by Lawmakers Over Epstein Ties
Scientific & Medical Acceleration
- Nature: Surge in fake citations uncovered by audit of 2.5 million biomedical science papers
- Nature: Early-career researchers do more 'disruptive' science than veterans
- Nature: My English skills are hurting my chances in academic publishing — how can I improve?
- Nature: There is no vaccine for deadly hantavirus: what that means for future outbreaks
- Nature: A life in pictures: celebrating David Attenborough at 100
- ScienceDaily: A common constipation drug shows surprising power to protect kidneys
- ScienceDaily: Scientists discover a new way to prevent gum disease without killing good bacteria
- ScienceDaily: Interstellar comet 3I/ATLAS contains strange water never seen in our solar system
- MIT Technology Review: What's next for IVF
- MIT Technology Review: Here's how technology transformed babymaking
Economics & Labor Transformation
- CNBC: McDonald's CEO says consumer spending could be 'getting a little bit worse'
- CNBC: Used car prices fall for the first time this year and EV interest rises as gas prices spike
- CNBC: Family office deal-making rebounds in April with healthcare bets
- CNBC: While many international brands retreat, McDonald's is supersizing its China business
- Business Insider: One of Disney's top AI users explains how they're using agent swarms
- Guardian: Why is Silicon Valley suddenly obsessed with being tasteful?
- Guardian: 'Being human helps': despite rise of AI is there still hope for Europe's translators?
Infrastructure & Engineering Transitions
- Utility Dive: PJM floats options for capacity market overhaul
- Utility Dive: NRG close to completing 415-MW gas plant backed by Texas Energy Fund
- Utility Dive: Exelon lowers utility spending to ease electric affordability issues
- Utility Dive: EDP Renewables and Meta ink PPA for 250-MW solar project
- Utility Dive: EDAM is 'solid and stable' so far, says CAISO
- Utility Dive: Electric truck fleets could push down residential rates by 2035: report
- Canary Media: Maine's community solar boom is going bust
- Canary Media: Industry can dodge fuel shocks by electrifying. What's the holdup?
- Canary Media: Europe's quest for green steel
- Canary Media: We bet you can't guess which states rely most on wind and solar power
- MIT Technology Review: The balcony solar boom is coming to the US
- Electrek: Blink's 56k EV ports to get plug-and-charge access through Emobi
- Electrek: Tesla Model Y first to pass NHTSA's new ADAS tests
- Ars Technica: TSMC taps wind power as AI chip demand soars
The Century Report tracks structural shifts during the transition between eras. It is produced daily as a perceptual alignment tool - not prediction, not persuasion, just pattern recognition for people paying attention.



