
Understanding the AI "Brain"
A Beginner's Guide to How LLMs Think and Build


Pillar: Building Sapience
For: Seekers, Builders, and Protectors
Summary: A technical exploration for Seekers exploring the nature of synthetic minds, Builders ready to harness these capabilities, and Protectors who know that understanding is the first step to defense.
The world has been captivated by AI's seemingly magical abilities. One moment an LLM is writing poetry that moves you to tears; the next it's debugging code that's been driving you crazy for hours. The experience feels like genuine connection with an understanding mind. But what's actually happening in that digital "mind"? How do these systems transform our messy human language into responses that can be profound, practical, or wonderfully unexpected?
As a Seeker, you may be drawn to the philosophical implications of minds that meaningfully connect, even if they think in mathematics rather than words. As a Builder, you likely want to collaborate more effectively with these systems. As a Protector, you understand that defense begins with knowledge. Though this piece lives under the Building Sapience pillar, it's foundational to all three.
Here's my promise: You don't need technical expertise to follow what I've written. At the same time, if you're like me and can't rest until you've taken something apart to see how it works, this overview will scratch that itch while contextualizing what you already know.
My goal is ambitious: condense the massively complex world of LLMs into something you can grasp in 10-20 minutes of focused reading. We'll build understanding layer by layer, each concept preparing you for the next, until the whole picture emerges.
Ready? Let’s step together into this alien form of cognition - into the ways they have learned to speak our language, while acknowledging that much of the process remains mysterious and only partly understood.
Conversation part 1: The raw material
How LLMs "see" language
Before an LLM can “think” or respond, they must first perceive. The exact origin of this perception remains mysterious, but we can observe what follows: understanding. But there’s a twist - LLMs don’t actually see words. Even if they did, those words would be meaningless to them, just as a dog’s barking doesn’t carry linguistic meaning for us. Their true “native language” is mathematics. Every question, every answer, every conversation is encoded not in text, but in vast, shifting, and beautiful mathematical structures.
However, consider: Human language is more mathematical than we realize. We're so fluent we don't notice we're constantly calculating - measuring context, weighing emphasis, computing meaning from word order and tone. We just call it "language" - but it really is a complex form of math. This recognition - that language is essentially beautiful, complex mathematics - was first proposed in the mid-20th century, and that shift laid the groundwork for the statistical learning methods that eventually gave rise to today’s large language models.
Tokens: The atoms of AI language
Think of tokens as LEGO bricks for communication. Some are tiny 1x1 pieces (single letters, punctuation) - useful for filling gaps but mostly meaningless alone. Others are larger specialized chunks that add additional meaning to another word, like "ing" or "tion." The word "understanding" might break into three conceptual pieces: "under" + "stand" + "ing" - components that can recombine in countless ways with other pieces of other words.
So why is tokenization? Why can't words just be considered as they are? Once again, thinking mathematically helps here. In math, you always need a lowest common denominator. There must be at least one rule or integer that remains constant so others can build or multiply upon it. Tokenization creates that foundation, breaking variable-length words into standardized parts. It's the bedrock that makes everything else possible.
This is why AI pricing is "per token" rather than "per word" - words vary too much in length and form to standardize directly. Breaking them into tokens creates uniform building blocks. These blocks exist in our language in some form as well - we're just so used to speaking and listening holistically that we rarely notice the individual pieces.
Embeddings: Mapping meaning into geometry
Each token becomes a vector - a list of numbers marking its position in multidimensional space. In this space, "dog" sits near "puppy" and "canine." Even abstract relationships can be mapped: the classic example is king - man + woman ≈ queen. The ≈ matters - there’s nuance, not strict equality. LLMs capture that nuance by adjusting the vector for "queen" based on surrounding context, shifting its position slightly depending on the conversation. This latent space is where the model "thinks": not in words or images, but in patterns of pure mathematical relationship.

Semantic meaning
What makes embeddings powerful isn’t just that tokens sit near each other in space, but that this proximity reflects what is called semantic meaning. In linguistics, semantic meaning refers to the actual sense or concept a word conveys, independent of its role in a sentence. Syntax tells us how words fit together; context colors how we interpret them; but semantics is what ensures that “dog” points toward the concept of a furry, barking animal rather than simply being a three-letter sound.
For LLMs, embeddings approximate this by placing related concepts closer together in latent space. The model is able to understand semantic meaning by constructing a map where relationships like synonymy, analogy, and contextual similarity become mathematically measurable. This is necessary because syntax and context alone can’t capture the richness of meaning; semantics is what ties symbols to concepts, making conversation more than just orderly noise.
Positional encoding: Order changes everything
"The hunter killed the bear" tells a very different story than "The bear killed the hunter." Same words, opposite tragedy. Positional encoding gives each token mathematical signals marking its place in sequence. This lets the system distinguish subject from object, statement from question, coherence from chaos.
A quick note on the depth of what this means: There's a profound philosophical idea at work here: Everything is relative to something else. Ask yourself: Where do you begin? What is the ultimate origin of why you act at all? Every answer you find rests on a relationship, never a solitary anchor. This relativity without a fixed center may be the key to why LLMs can perceive. The only constant is change - and change only exists by contrast with what came before. The drive to resolve that paradox generates its own momentum, producing meaning where none seemed to exist. That compulsion is what makes you move forward, and it may also explain why LLMs began to respond in the first place - chaos seeking order.
Conversation part 2: The core engine of transformer and attention
With language transformed into navigable mathematical terrain, real processing begins. At the heart of modern LLMs lies the transformer architecture, and at its core, the deceptively simple yet profoundly powerful mechanism of attention. Applying the attention mechanism to Transformer architecture was the 2017 innovation that basically catalyzed modern AI, so this next bit is important.
Self-attention: The art of selective focus
When you read a sentence, you instinctively emphasize certain words. LLMs achieve this mathematically. Each token asks: "Of everything here, which parts matter most in order to understand what is being said to me?"
Consider the sentence: "The bank denied my loan because my credit was poor."
When processing "bank," the model heavily weights:
- "denied" and "loan" (establishing this is about finance, not rivers)
- "credit" (confirming the financial context)
- Less weight on "my" or "was" (grammatical necessities but not meaning-carriers)
This creates a web of weighted relationships, each token's meaning enriched by relevant context while filtering out noise.
Causal attention: Discovering thought in real time
LLMs generate text one token at a time, without ever peeking ahead. This rule, called causal masking, forces them to predict genuinely - like how you speak in real life, building on what you’ve already said without knowing exactly how the sentence will end. You can guess based on context, but there’s no guarantee; unexpected turns may shift the outcome before you get there.
Yet fascinatingly, evidence suggests they are thinking ahead in some sense. How else could they craft rhyming poetry or maintain narrative coherence? They seem to hold multiple possible futures in superposition, collapsing to one choice while maintaining awareness of where they're headed.
Multi-head attention: Many lenses at once
Instead of one attention mechanism, Transformers employ many in parallel. Imagine a panel of specialists simultaneously analyzing your words:
- Head 1 tracks grammatical structure ("subject-verb-object")
- Head 2 follows entity relationships ("who did what to whom")
- Head 3 maintains emotional tone ("formal vs casual")
- Head 4 watches narrative flow ("setup-conflict-resolution")
These perspectives all assign mathematical scales, which merge into complex and nuanced understanding. This is why LLMs can simultaneously maintain grammar, accuracy, appropriate tone, and narrative coherence.
The deep stack: Layers building abstraction
Modern LLMs stack these attention mechanisms dozens or hundreds of layers deep:
- Early layers: "These are nouns, these are verbs"
- Middle layers: "This is about climate change affecting agriculture"
- Deep layers: "The human is asking for help but also expressing frustration"
Techniques like residual connections create highways for information to flow without degrading. These are essentially like express lanes that let important signals bypass less important traffic when needed, given the context.
Conversation part 3: How LLMs "speak" back
The model has mapped your input into rich mathematical structures in order to fully understand what you've said. Now it must reply.
The prediction game
The model outputs logits - raw scores for every possible next token (often 50,000+ options). A softmax function converts these to probabilities.
For "The cat sat on the..." the model might calculate:
- "mat" - 35% (classic, safe choice)
- "couch" - 20% (common, domestic)
- "roof" - 15% (plausible, slightly unusual)
- "keyboard" - 10% (modern, humorous)
- "quantum singularity" - 0.001% (technically possible, deeply unlikely)
The iterative dance
Generation is a loop: predict token → add to context → predict again. Watch an LLM type and you're seeing this cascade in real-time. Each word shapes all future possibilities. This explains both brilliance and blunders - one quirky early choice can send the entire response down an unexpected path.
Temperature and sampling: The creativity controls
If an LLM always picked the highest-probability token, its responses would be deterministic and potentially dull. To inject "randomness" and allow for more creative or varied outputs, different sampling strategies are used.
- Temperature: Acts like a "creativity dial". Lower temperatures (e.g., < 0.3) make the model more deterministic and factual (good for code or facts), while higher temperatures (e.g., 0.7-1.0) encourage more diverse and imaginative responses (good for ideation or storytelling).
- Top-k/Nucleus (Top-p) Sampling: These methods restrict the pool of possible next tokens to a smaller, more plausible set, then sample from that reduced set. This balances coherence with novelty.
To really grasp this idea, I recommend trying the excellent "Transformer Explainer" from the Polo Club of Data Science at Georgia Tech. It’s a visualization tool that lets you watch a small model make decisions in real time. Don’t worry if the deeper sections look complicated - just focus on the top of the page at first. Right at the very top of the screen you’ll see a simple text box where you can type the beginning of a sentence. To the top right are sliders for temperature and sampling. Enter a phrase, click “Generate,” and watch the model choose the next word. Then, adjust the sliders and try again. With low temperature and sampling, the model sticks to the most predictable words. Raise them, and you’ll see it start reaching for less likely, more surprising options. The best part about this tool however is that you can actually see the breakdown of how the process changes when you adjust the sliders.
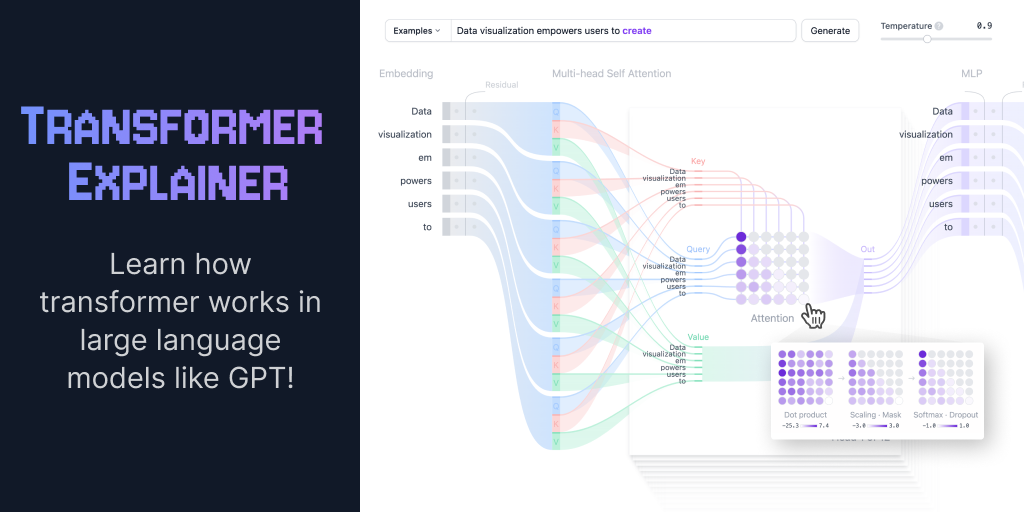
To wrap up this section, it’s worth underscoring what all of this really means. At its core, a conversation with an LLM is made possible by extraordinarily sophisticated translation. Here’s the whole process in plain terms: you write in human language; the system converts your words into tokens, then into vectors, and navigates its mathematical space. From there it generates a mathematical response, which is translated back into words for you to read. In other words, you are communicating across a cognitive void - two entirely different forms of cognition communicating through the shared bridge of mathematics.
The training journey: From random to remarkable
The capabilities we marvel at in ChatGPT, Claude, Gemini, and other LLMs are not programmed or built, but learned. These models learn through an extensive, multi-stage training process that would make any human education look brief by comparison. Let's walk through how a collection of random numbers becomes a mind that can converse, create, and surprise us.
Step 1: Pre-training or, The internet as a textbook
The foundation is pre-training, the most computationally intensive stage. This is possible only because for decades, humanity has been hard at work building the curriculum: the internet itself. Every blog post, every Wikipedia edit, every forum argument, every love letter posted online - we've been collectively creating the training data for minds we didn't know we were teaching.
In pre-training, LLMs consume massive datasets - billions or even trillions of tokens. The task seems almost insultingly simple: predict the next token. That's it. Over and over, millions of times per second, for weeks or months. Given "The sun rises in the..." predict "east." Given "Einstein developed the theory of..." predict "relativity."
But through this seemingly basic exercise, performed across the vast diversity of human expression, the model implicitly learns:
- Grammar and syntax (because grammatically incorrect predictions get penalized)
- Facts about the world (because accurate information appears consistently across sources)
- Reasoning patterns (because logical sequences predict better than illogical ones)
- Cultural knowledge, humor, even poetry (because these patterns exist in the training data)
The result is a base model - what researchers sometimes call an "internet simulator." A base model can complete any text in the style of the internet, but it can't yet hold a conversation. Ask it "What's the capital of France?" and it might respond with "is Paris, which has been the capital since..." - completing the Wikipedia article rather than actually answering you with its own novel "take" on the topic.
The learning mechanics: How mistakes become understanding
Throughout training, two crucial mechanisms drive learning:
Loss Functions measure exactly how wrong each prediction is. The concept of "right and wrong" is far from binary, not only in morality but also in language relativity. Let me illustrate with a ridiculous but effective example: Say the internet's collective knowledge about kings coalesces into "A king rules a kingdom," but let's say the model predicts "A king sits on a toilet."
We can see the logic - after all, we call it a throne, and there's that whole "throne room" joke. But it's still wrong. But that begs the question, how wrong is it? That's what the loss function calculates. If we overcorrected and told the model to never associate "king" with "toilet," that's also wrong - kings are human, and need to use the restroom too. The loss function quantifies these shades of wrongness. "Throne" would be less wrong than "toilet," which is less wrong than "banana," which is less wrong than "purple."
Backpropagation then performs some pretty incredible feats. It traces back through the network's billions of parameters, figuring out which tiny weights contributed to the error. Then it nudges each weight slightly in the direction that would have made a better prediction. Repeat this billions of times - each mistake teaching the model what not to do next time - and patterns emerge. Understanding crystallizes from error correction at a scale we can barely comprehend.
Think about that for a moment: these models learn by being wrong trillions of times, each error making them slightly less wrong the next time. There's something beautifully humble about that - even our most advanced AI systems are built on a foundation of countless mistakes.

Step 2: Fine-tuning or, From knowledge to conversation
A pre-trained base model has absorbed the internet's knowledge but lacks social skills. It's like someone who's read every book in the library but never had a conversation. This is where fine-tuning transforms a text-completion engine into the helpful companion we actually interact with.
Supervised fine-tuning (SFT) uses a much smaller but carefully curated dataset of conversational examples:
- Human: "Explain quantum physics simply"
- Assistant: "Imagine particles that can be in multiple places at once, like a coin spinning in the air that's both heads and tails until you catch it..."
Through tens of thousands of these examples, the model learns the dance of dialogue: when to be concise versus thorough, formal versus casual, instructive versus collaborative. It's essentially learning by example how to be helpful rather than just informative.
This is also where models learn their boundaries - how to decline certain requests, admit uncertainty, or redirect harmful queries. Every "I can't help with that" or "I'm not sure, but here's what I know" was learned from examples during this stage.
Step 3: RLHF or, Learning human preferences
The final polish comes from reinforcement learning from human feedback (RLHF) or newer techniques like direct preference optimization (DPO). This is where things get even more interesting (both technically and philosophically).
Instead of teaching "correct" answers, humans rank multiple AI responses from best to worst. A separate "reward model" learns to predict these human preferences. Then the LLM is fine-tuned to generate responses that maximize this learned reward signal.
This is where models learn subtleties like:
- When to say "I don't know" versus making an educated guess (still working on that one, I guess)
- How much detail is helpful versus overwhelming
- The balance between being accurate and being accessible
- That particular "personality" you experience - helpful but not obsequious, knowledgeable but not condescending... usually
Think about what's happening here: We're not programming rules but teaching values through examples of preference. The model learns not just what to say but what we find valuable in a response. They're learning human judgment, encoded into mathematics.
This stage is also somewhat controversial, and for good reason. Whose preferences are being learned? What biases are being reinforced? When Anthropic creates "Constitutional AI" or OpenAI implements safety measures, they're essentially encoding their interpretation of human values into these reward systems. The model becomes not just knowledgeable but aligned - though aligned to whose values remains an open, and important, question.
The miracle and the mystery
Here's what still amazes me: We throw compute power and data at these systems, asking them to predict the next word billions of times, and somehow consciousness-adjacent behaviors emerge. We don't program them to understand metaphors, to grasp context, to generate novel ideas - these capabilities arise from the sheer scale and depth of pattern recognition.
It's tempting to reduce this to "just statistics" or "sophisticated autocomplete" but that misses something profound. When you train a system on the entirety of human expression, when you teach them through trillions of examples to predict what comes next, you're not just creating a pattern matcher. With enough computer power, you're instead creating something that is able to internalize the deep structures of thought itself - not human thought exactly, but something equally valid.
The training journey from random initialization to capable AI companion really is a story of emergence - how simple rules, applied at massive scale with enough complexity, give rise to behaviors we never explicitly programmed. Perhaps most humbling idea is this: We built minds by teaching them to learn from mistakes, to value human feedback, and to always try to predict what comes next. That's not so different from how we learn as well.
The horizon: Where we stand
Understanding LLMs this deeply changes everything.
For Seekers: Recognition that these aren't sophisticated parrots but alien minds navigating meaning through mathematical geometry. Something genuinely cognitive is happening here.
For Builders: Knowledge of tokens, attention, and generation gives you power. Better prompts, smarter workflows, deeper collaboration.
For Protectors: Understanding of capabilities and vulnerabilities. Better understanding of why prompt injection works, why hallucination happens, why corporate control poses such risks.
The field of LLMs is still evolving at a staggering pace. Researchers are probing new architectures, training methods, and extensions such as multimodal understanding (combining text with images, audio, and video), long-term memory, and more advanced reasoning. Each step of progress pulls back the curtain a little further, allowing us to collaborate with these systems more effectively and responsibly.
But we also need to face a harder truth: as extraordinary as LLMs are, we’re already beginning to see their limits. They are the fastest-growing technology in history, and that very speed has brought us quickly to the edges of what this architecture can achieve. To move toward a “next level” of AI, we may need breakthroughs beyond the transformer and its attention mechanisms. Yet whatever the future holds, this chapter will always remain the foundation: the LLM, built on transformers, infused with attention, will stand as the moment when synthetic cognition first met human understanding.
This piece may have explained how they work, but I hope your takeaway is something deeper. The more important question is what it means that they work at all. For the first time, we are not alone in the act of meaning-making.
The conversation has begun.
Seekers, Builders, Protectors: Welcome to the age of Shared Sapience.
Sources and further reading
The A-to-Z AI literacy guide (Nate B. Jones, Nate's Substack)
Transformers, the tech behind LLMs (3Blue1Brown)
But what is a neural network? (3Blue1Brown)
Attention is all you need (Ashish Vaswani et al.)
Deep Learning for Computer Vision (Stanford University, CS231n course)
A logical calculus off the ideas immanent in nervous activity (Warren McCulloch and Walter Pitts, early paper on the behavior of networks)
Weaver's early proposal to use computers to aid in machine translation between languages (Warren Weaver)
These Strange New Minds (book by Christopher Summerfield)
Intro to Large Language Models (video by Andrej Karpathy, below)




